Reinforcement Learning via Self-Distillation
Jonas Hübotter1, Frederike Lübeck*,1,2, Lejs Behric*,1, Anton Baumann*,1, Marco Bagatella1,2, Daniel Marta1, Ido Hakimi1, Idan Shenfeld3, Thomas Kleine Buening1, Carlos Guestrin4, Andreas Krause1
1ETH Zurich 2Max Planck Institute for Intelligent Systems 3MIT 4Stanford
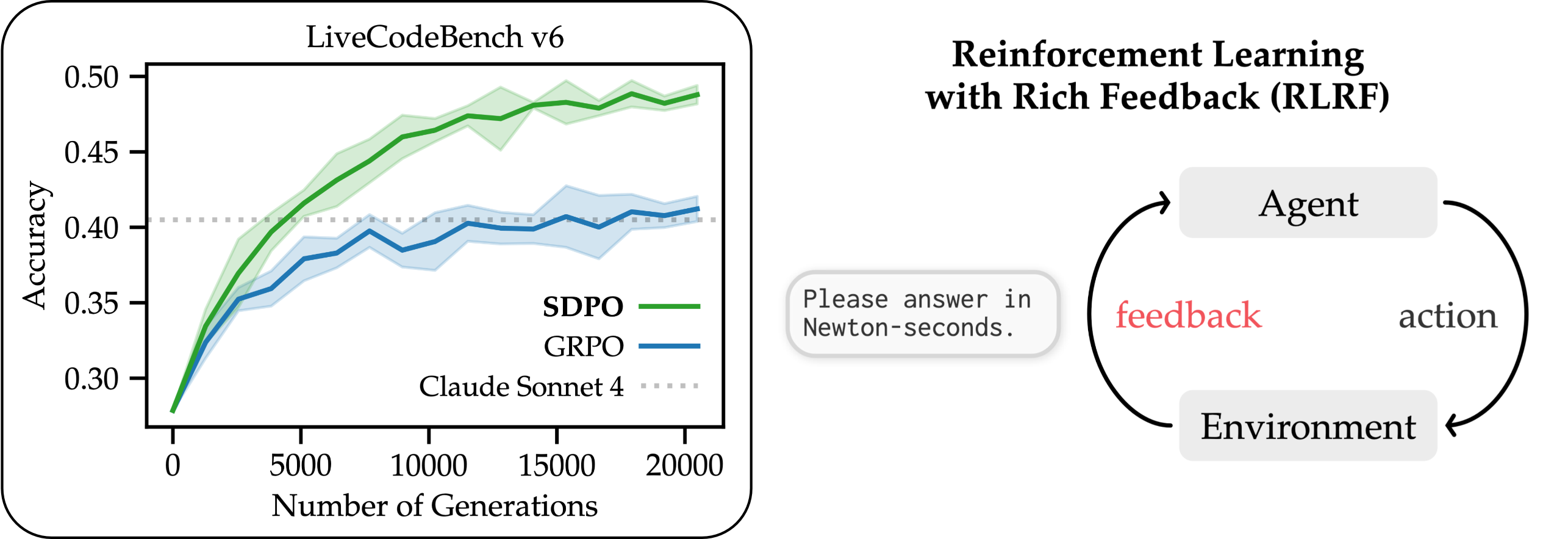
Abstract
Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.

Learning to Reason Better, Faster
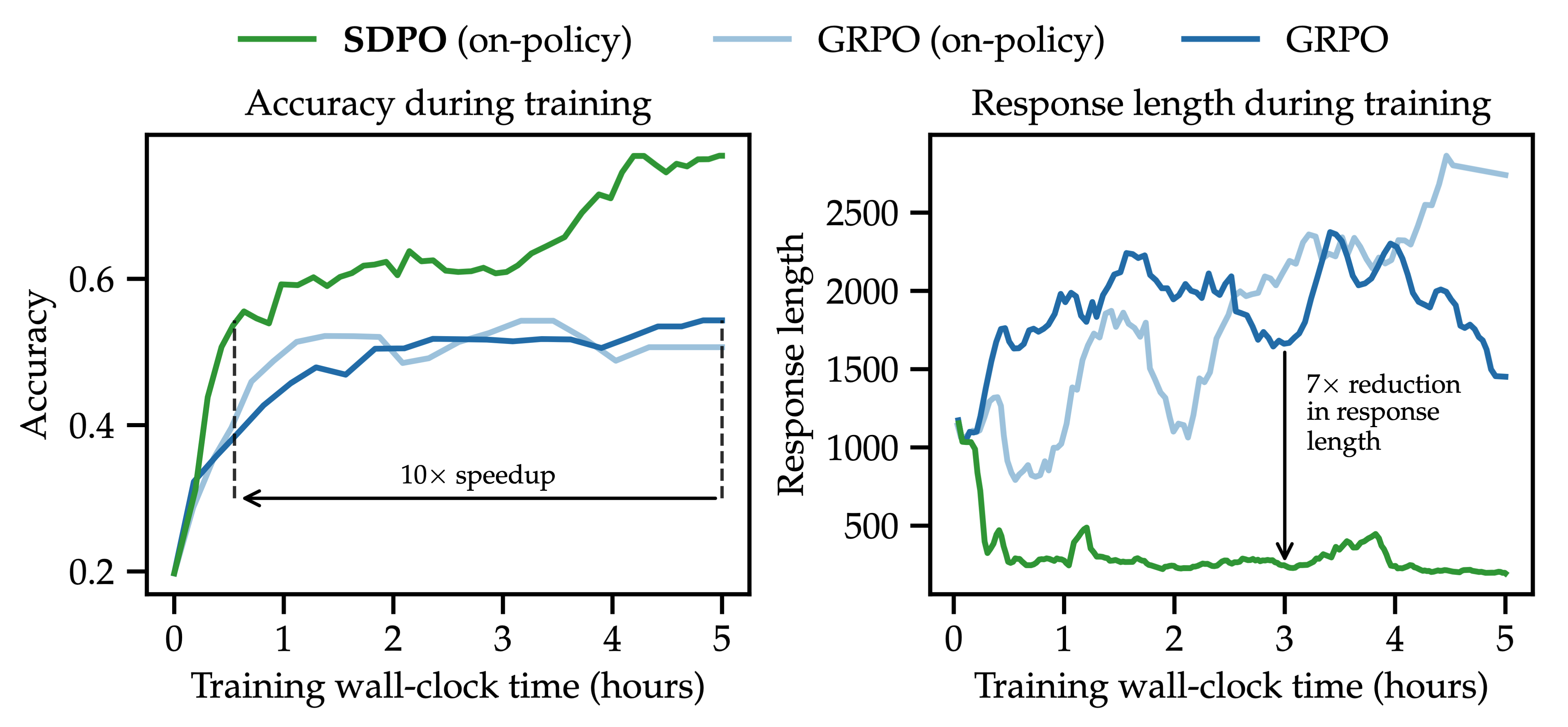
Even when the environment provides only a scalar outcome reward, SDPO outperforms GRPO substantially. SDPO uses successful rollouts as implicit feedback, allowing the policy to directly learn from its own best generations, without requiring external demonstrations or additional datasets. On undergrad-level Chemistry questions (shown above with Olmo3-7B-Instruct), SDPO reaches GRPO's accuracy 6× faster (wall-clock time) and reaches a much higher final accuracy. This shows that self-distillation can remove the credit-assignment bottleneck of today's RLVR methods. Reasoning traces after SDPO are up to 11× shorter than those of GRPO which often enters logical loops, highlighting that effective reasoning need not be verbose.
Test-Time Self-Distillation Accelerates Discovery
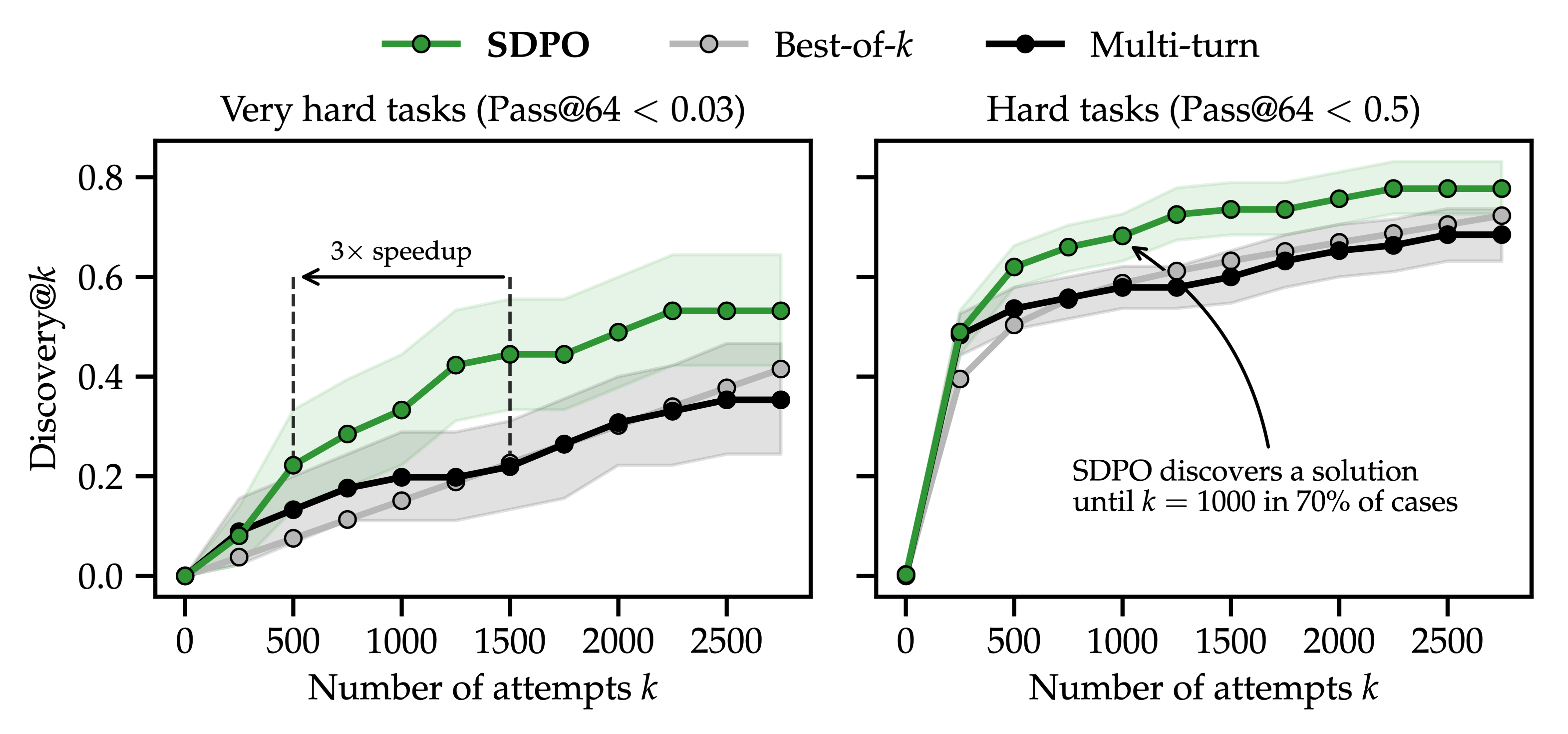
SDPO can also be applied at test time to a single hard question by repeatedly distilling the model with environment feedback into the current policy. With binary rewards, RLVR provides no learning signal before the first success, so it cannot accelerate discovery in the same way. SDPO accelerates the discovery of solutions to very hard problems of LiveCodeBench (pass@64 < 0.03). It achieves the same discovery probability (discovery@k = P(solution found within k attempts)) as best-of-k sampling and multi-turn prompting with up to ~3× fewer attempts, and discovers solutions the baselines fail to find at all. Rich environment feedback (such as runtime errors) turns repeated failures into a dense learning signal, enabling SDPO to progress even before the first solution is found.
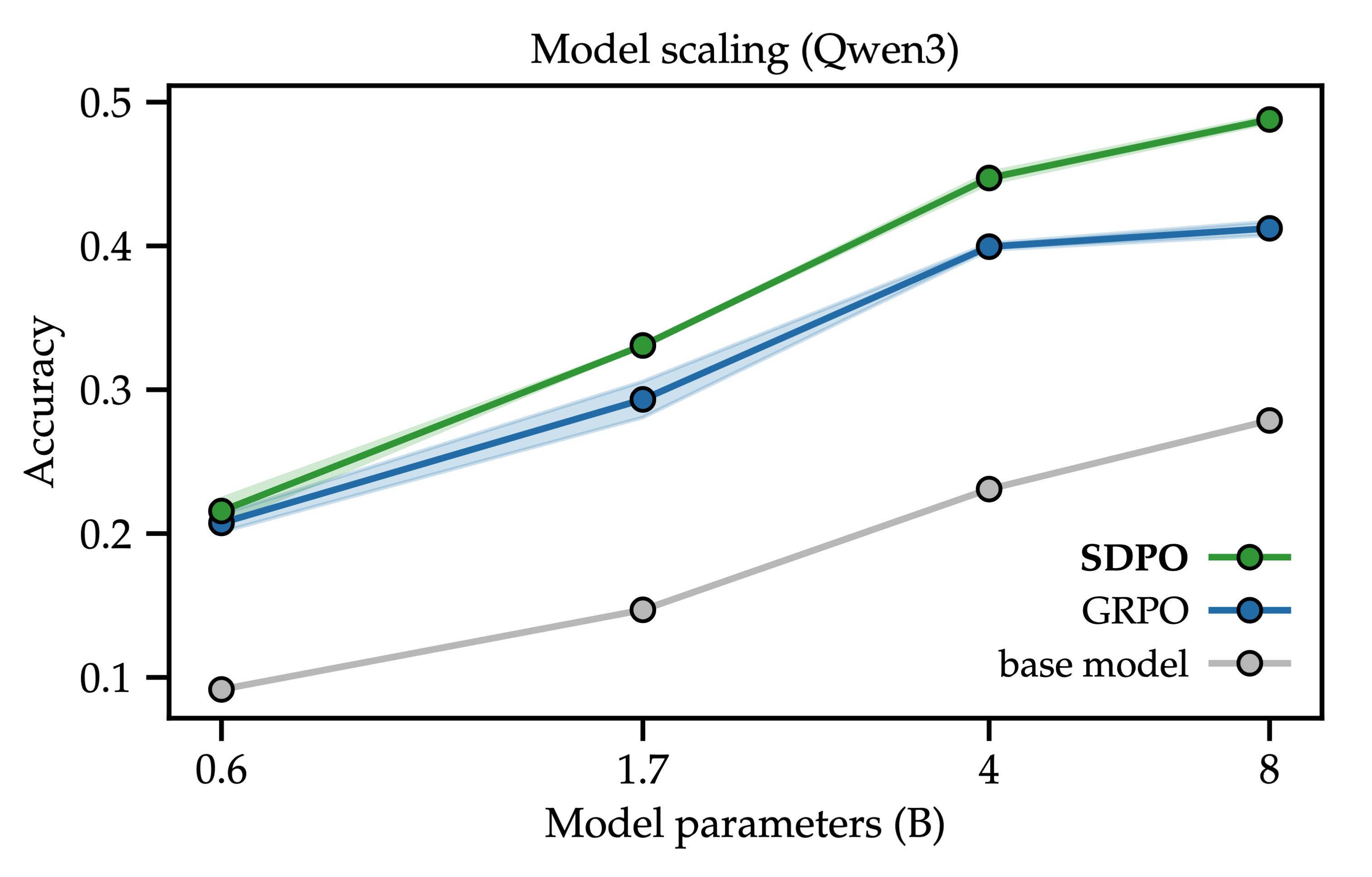
SDPO Benefits from Model Scale
SDPO's gains grow with model size. Across Qwen3 models (0.6B→8B), SDPO consistently outperforms GRPO, with the gap widening as models become stronger. This suggests that accurate retrospection of the self-teacher emerges with scale as models become better in-context learners, making self-distillation increasingly effective for larger LLMs.
SDPO Performs Dense Credit Assignment
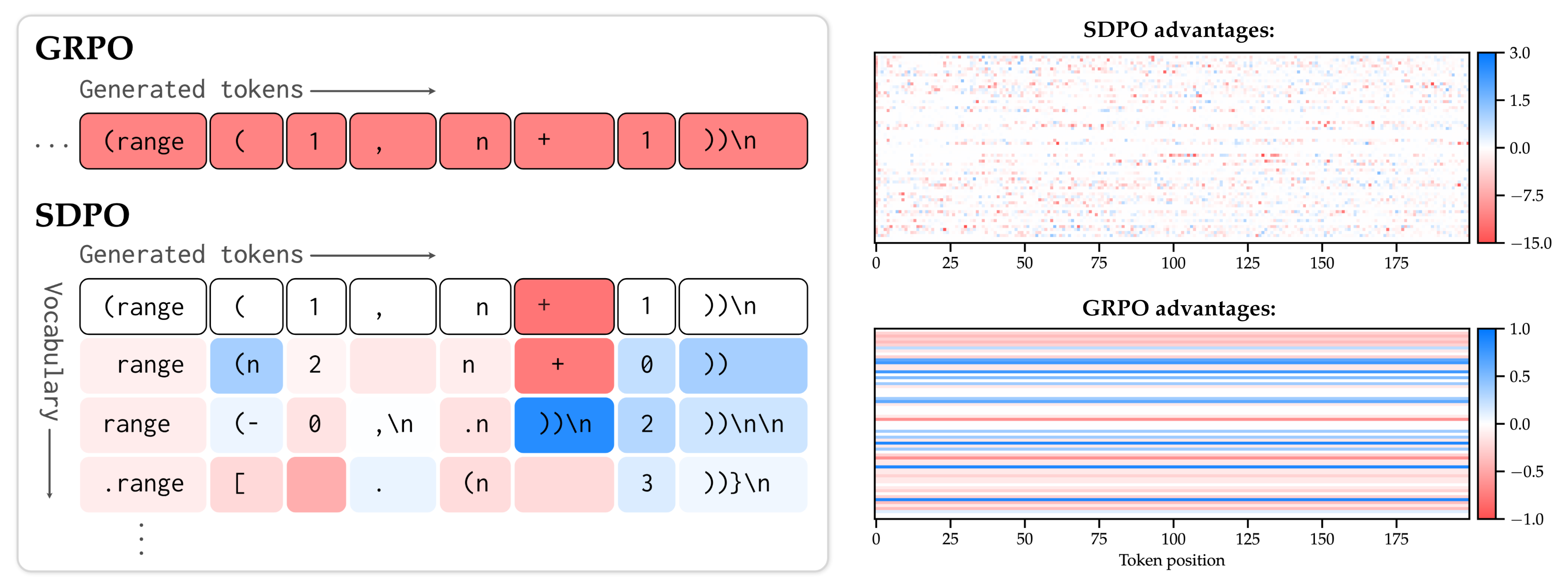
SDPO provides dense credit assignment by comparing the student's next-token distribution to the self-teacher's distribution with in-context feedback. SDPO assigns positive/negative advantages when the self-teacher becomes more/less confident than the student, providing dense supervision along the student's attempts. This targeted signal is consistent with both SDPO's faster learning and its convergence to more efficient reasoning.
Bibtex
@article{hubotter2026reinforcement,
title = {Reinforcement Learning via Self-Distillation},
author = {Hübotter, Jonas and Lübeck, Frederike and Behric, Lejs and Baumann, Anton and Bagatella, Marco and Marta, Daniel and Hakimi, Ido and Shenfeld, Idan and Kleine Buening, Thomas and Guestrin, Carlos and Krause, Andreas},
year = {2026},
journal = {arXiv preprint arXiv:2601.20802},
}