Self-Distillation Enables Continual Learning
Idan Shenfeld1, Mehul Damani1, Jonas Hübotter2, Pulkit Agrawal1
1MIT 2ETH Zurich
Paper: https://arxiv.org/abs/2601.19897
Code: https://github.com/idanshen/Self-Distillation
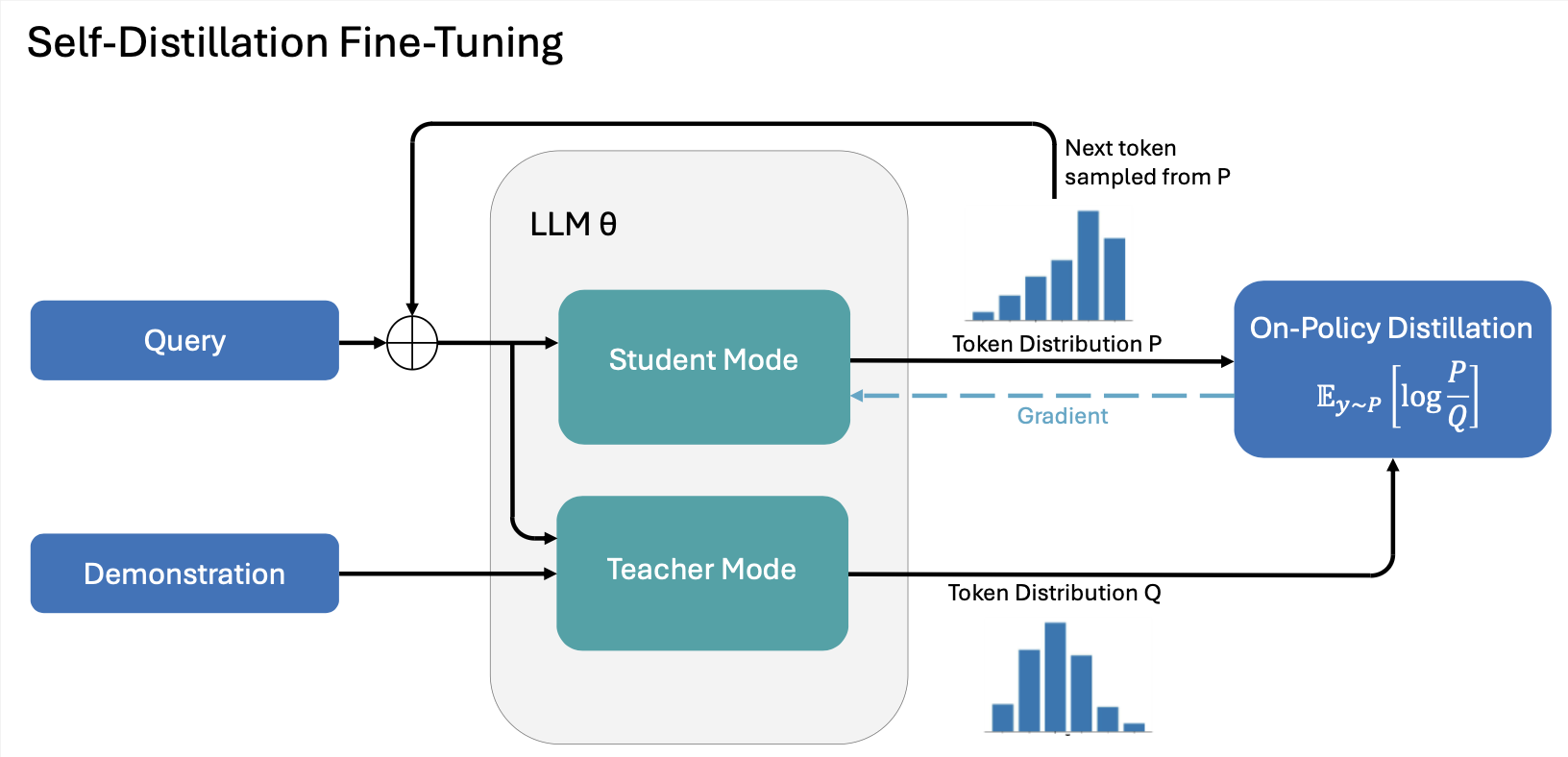
Abstract
Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce On-Policy Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.
Learning without forgetting
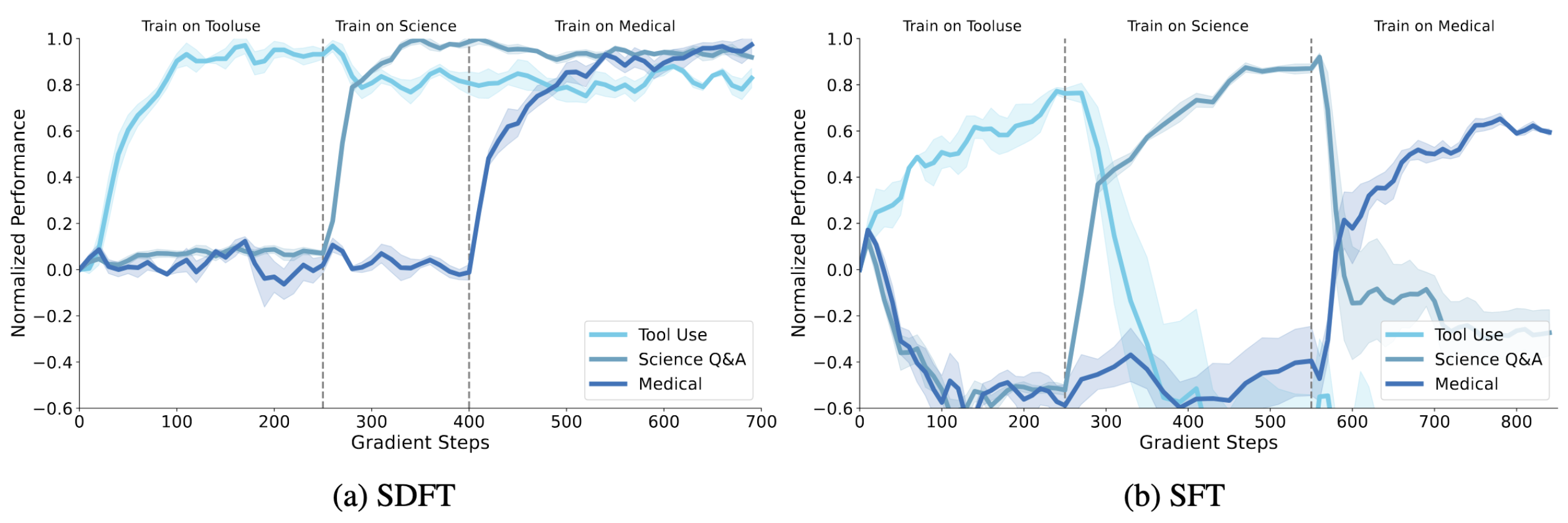
In a challenging continual learning experiment, we train a single model sequentially on three different tasks. SDFT successfully learns each new task while retaining performance on previous ones. In contrast, SFT exhibits severe interference—performance on earlier skills rapidly degrades once training shifts to a new task. This demonstrates that SDFT supports true continual learning, allowing incremental skill acquisition without catastrophic forgetting.
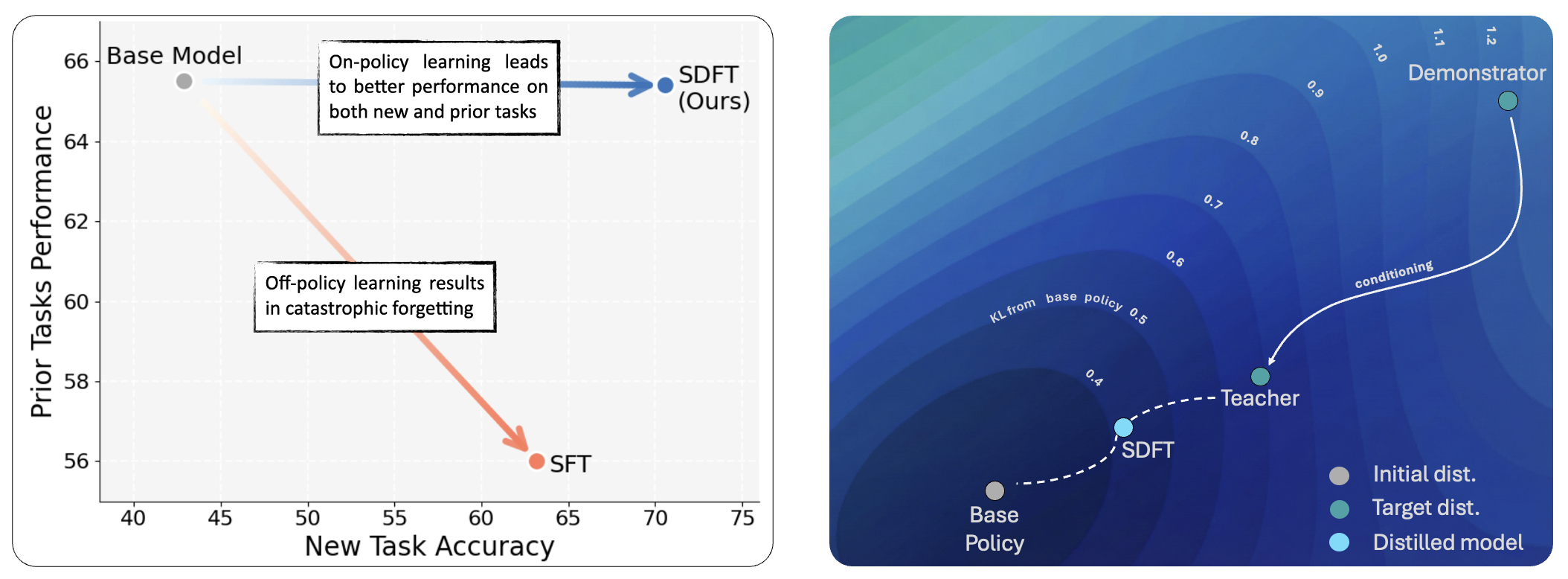
On-policy Learning Leads to Better Generalization
Beyond reducing catastrophic forgetting, we discovered that SDFT actually learns new tasks better than SFT. Across multiple skill-learning and knowledge-acquisition tasks, models trained with SDFT consistently achieve higher performance (in-distribution generalization) than those trained with supervised fine-tuning. Why? Off-policy learning trains only on expert-induced trajectories—but at test time, small errors can push the model into states it never saw during training, causing compounding mistakes. SDFT, as an on-policy self-distillation algorithm, avoids this mismatch by training on the model's own generated trajectories, teaching it to recover from its own errors rather than just memorizing expert paths.
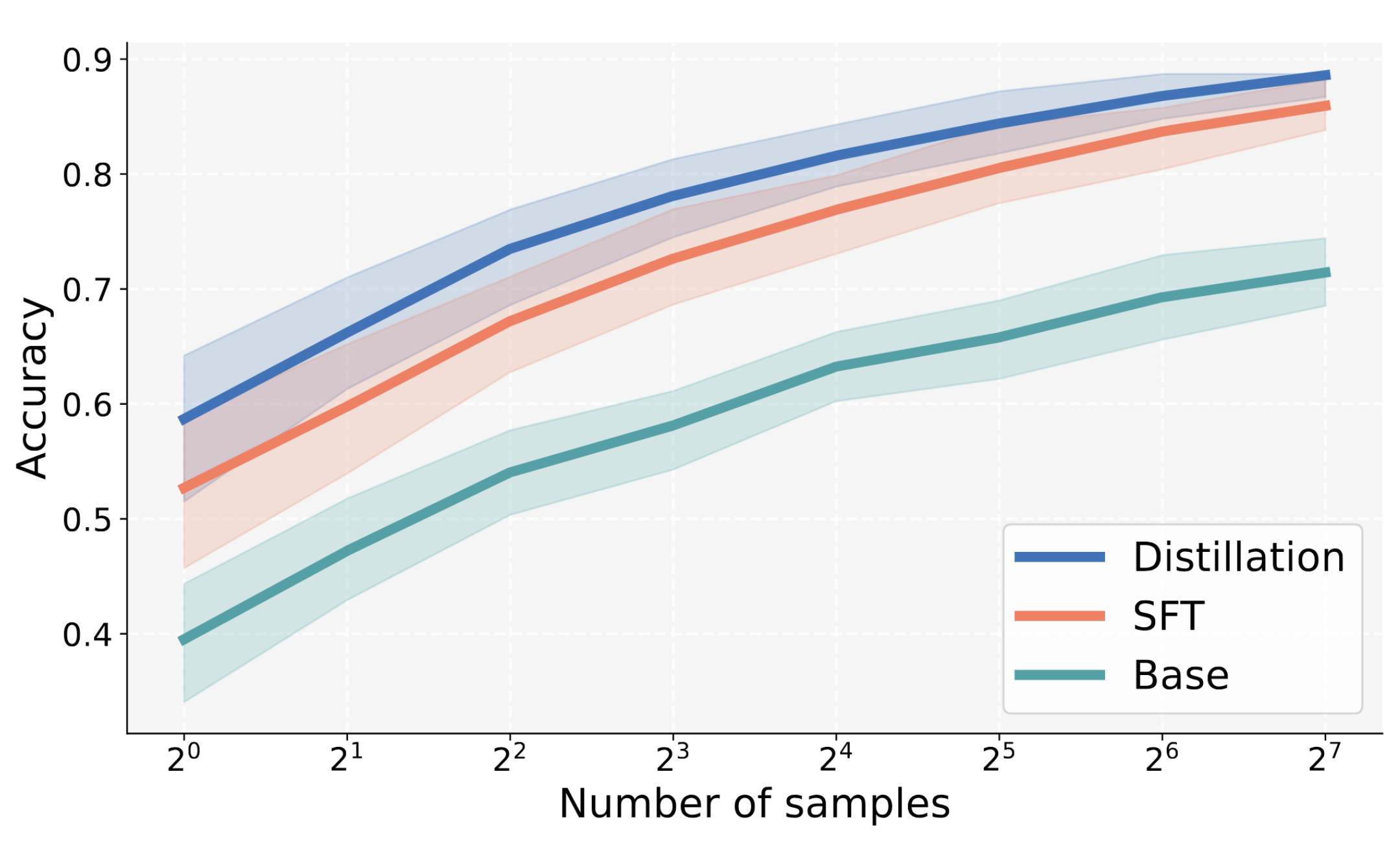
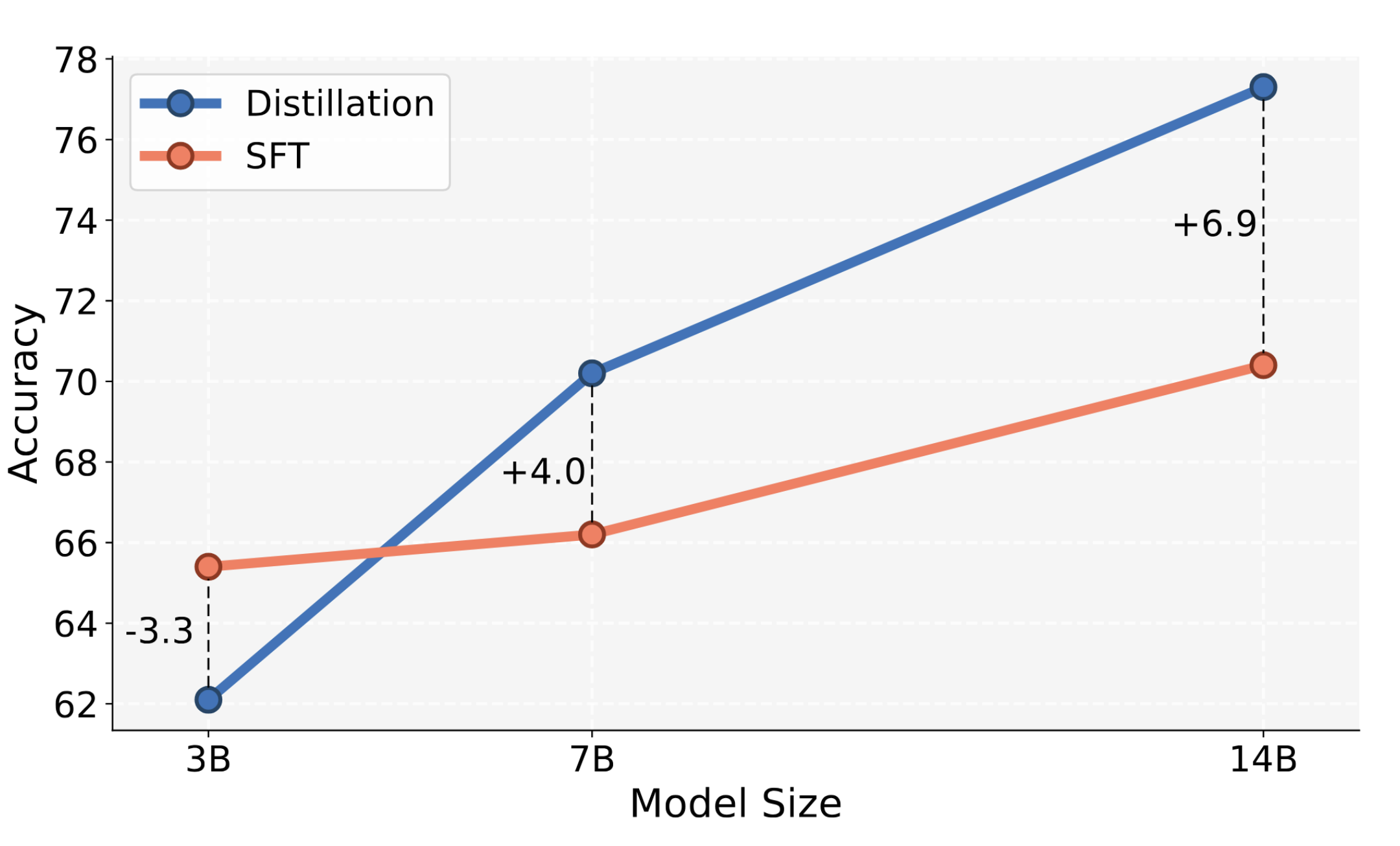
SDFT Benefits from Model Scale
The stronger a model's in-context learning, the better SDFT works. At 3B parameters, the model's ICL ability is too weak to provide meaningful teacher guidance, and SDFT underperforms SFT. But as we scale up, the gains grow consistently: the 7B model achieves a 4-point improvement over SFT, and the 14B model widens the gap to 7 points. This trend suggests that with frontier models and their strong in-context reasoning, SDFT's advantages will only become more pronounced.
Bibtex
@misc{shenfeld2026selfdistillationenablescontinuallearning,
title={Self-Distillation Enables Continual Learning},
author={Idan Shenfeld and Mehul Damani and Jonas Hübotter and Pulkit Agrawal},
year={2026},
eprint={2601.19897},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2601.19897},
}