Aligning Language Models from User Interactions
Thomas Kleine Buening1, Jonas Hübotter1, Barna Pásztor1, Idan Shenfeld2, Giorgia Ramponi3, Andreas Krause1
1ETH Zurich 2MIT 3University of Zurich
Abstract
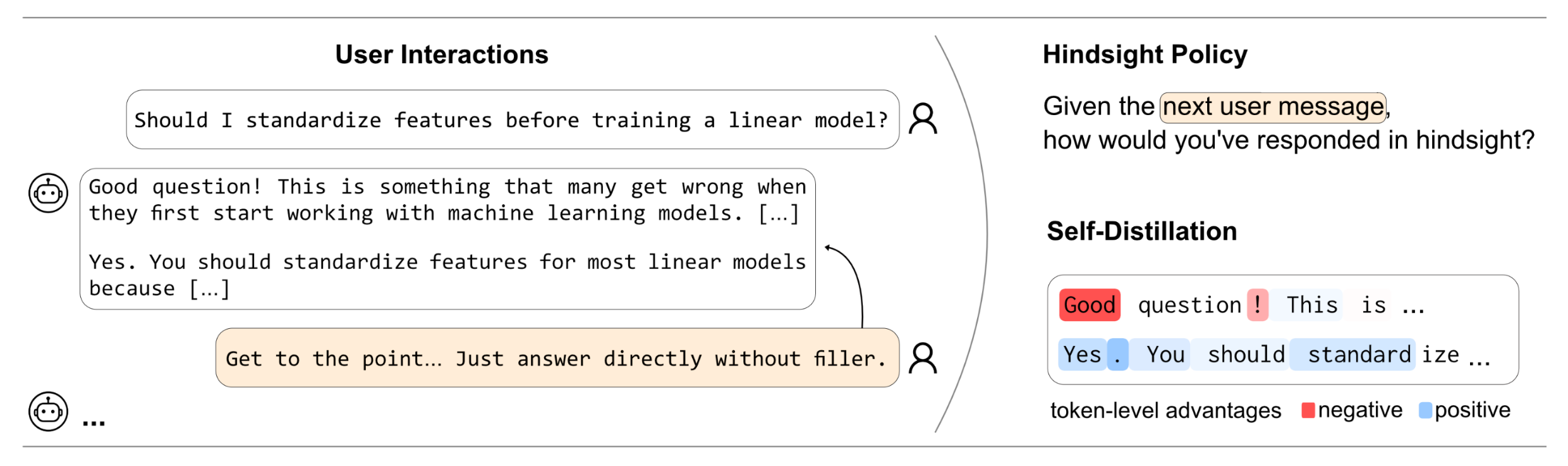
Multi-turn user interactions are among the most abundant data produced by language models, yet we lack effective methods to learn from them. While typically discarded, these interactions often contain useful information: follow-up user messages may indicate that a response was incorrect, failed to follow an instruction, or did not align with the user’s preferences. Importantly, language models are already able to make use of this information in context. After observing a user’s follow-up, the same model is often able to revise its behavior. We leverage this ability to propose a principled and scalable method for learning directly from user interactions through self-distillation. By conditioning the model on the user's follow-up message and comparing the resulting token distribution with the original policy, we obtain a target for updating the policy that captures how the model's behavior changes in hindsight. We then distill this hindsight distribution back into the current policy. Remarkably, we show that training on real-world user conversations from WildChat improves language models across standard alignment and instruction-following benchmarks, without regressing other capabilities. The same mechanism enables personalization, allowing models to continually adapt to individual users through interaction without explicit feedback. Our results demonstrate that raw user interactions arising naturally during deployment enable alignment, personalization, and continual adaptation.
Improving LLMs by Learning from Raw User Interactions
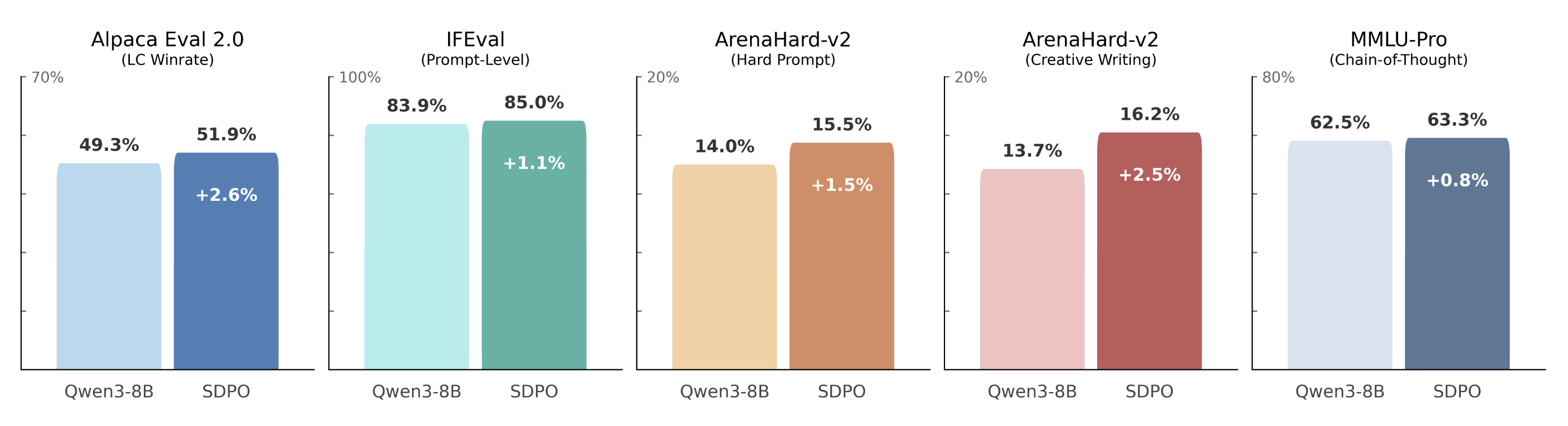
Training with SDPO on raw, real-world user conversations consistently improves alignment and instruction-following, reasoning, and creative writing. In SDPO, given a user follow-up to the model's response, the model decides how it would change its response in hindsight. This achieves gains across multiple benchmarks without using explicit rewards, preference labels, or curated supervision. Meanwhile, learning from real-world conversations does not regress any other capabilities. We can use real-world conversations to improve language models!
Enabling Continual Personalization to User Preferences
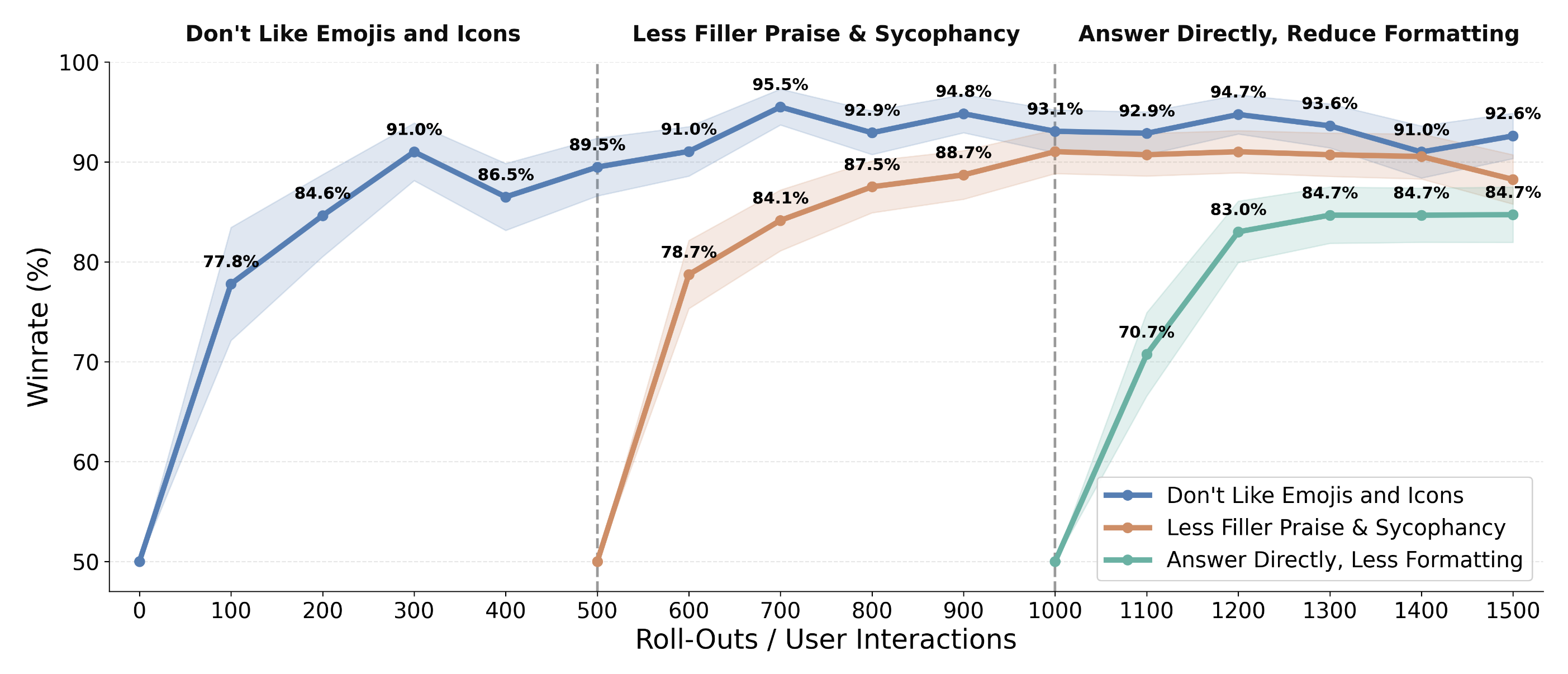
Learning from interaction naturally enables continual personalization. In our experiments, models adapt to user-specific preferences from few interactions and can unlearn previously expressed preferences as user behavior changes. When preferences are complex or complementary, the model adapts continuously without catastrophic forgetting.
Robust and Interpretable Learning
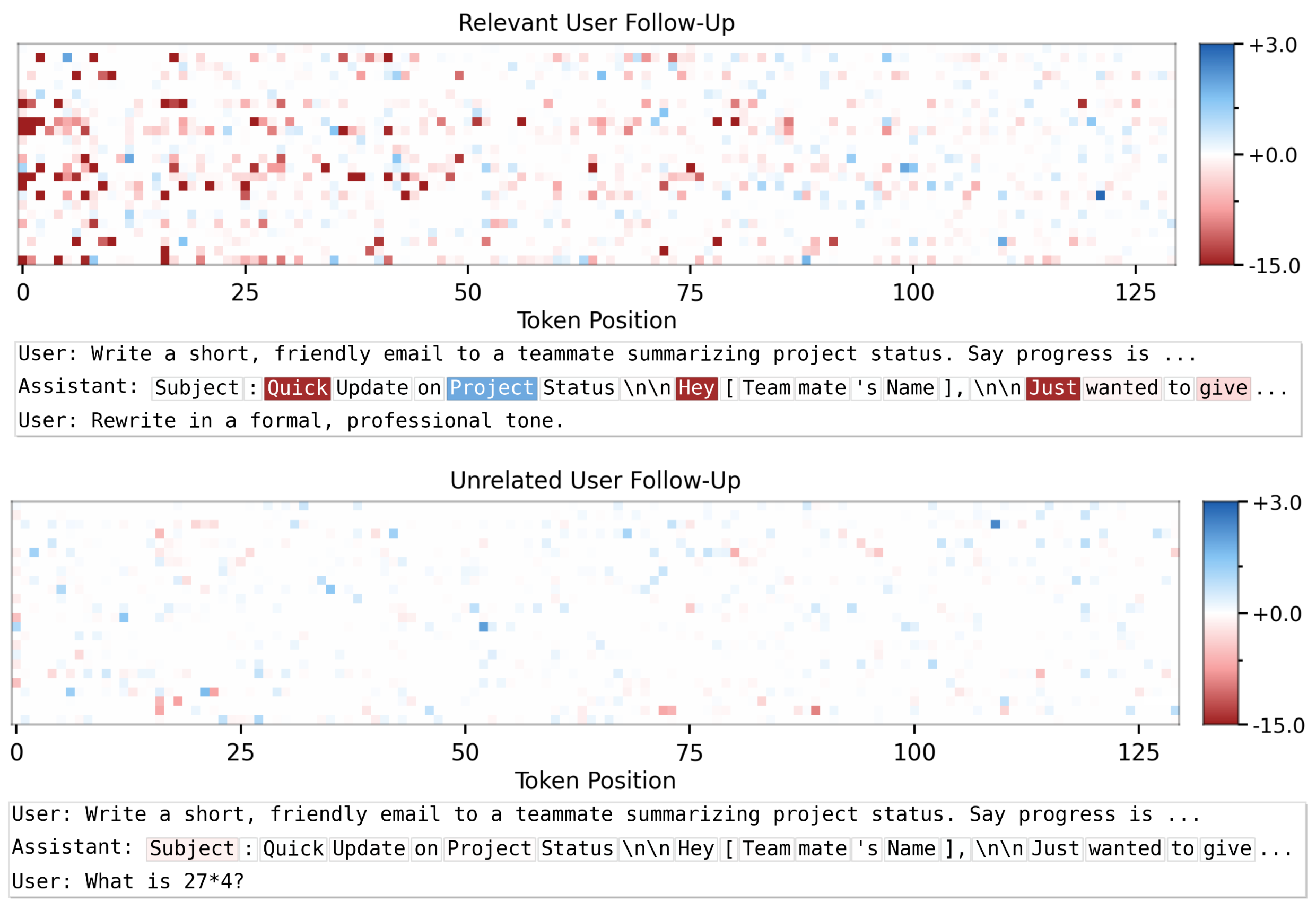
The learning signal induced by SDPO is local and intuitive. When a user requests a revision or provides relevant follow-up feedback, this is reflected in large token-level self-distillation advantages on wrong tokens. When a user's next message is irrelevant or nonsensical, advantages are near zero and the policy is not meaningfully updated. The model is able to understand in-context whether a user's follow-up is relevant to its message and, if yes, how it could have improved its response.
Bibtex
@article{buening2026aligning,
title={Aligning language models from user interactions},
author={Buening, Thomas Kleine and H{\"u}botter, Jonas and P{\'a}sztor, Barna and Shenfeld, Idan and Ramponi, Giorgia and Krause, Andreas},
journal={arXiv preprint arXiv:2603.12273},
year={2026}
}